Sur le blog Data & Analytics, sur lequel BBVA rend compte de ses recherches et développements en matière de traitements des données, un récent article fait état, parmi les nouveaux services proposés aux clients, des avancées en matière de prévision des soldes en comptes et des apports que l’IA est à même de fournir à ce propos. Une démarche intéressante mais qui amène à poser quelques questions… essentielles.
Actuellement l’appli mobile de BBVA donne aux utilisateurs une estimation de l’état du solde sur leur compte courant principal à la fin du mois. Cela permet évidemment de mieux maitriser ses dépenses. Mais, uniquement fondée sur la répétition de certaines charges et revenus, la mesure peut être assez éloignée de la réalité. Elle n’intègre pas une dimension d’incertitude, tenant simplement à ce que les utilisateurs peuvent engager des dépenses nouvelles, inhabituelles. Dès lors, il doit être possible d’aller plus loin et de rendre l’estimation plus fiable en raisonnant – c’est ce que décrit l’article – de manière probabiliste.
Pour cela, il s’agit d’ajouter au modèle de prévision utilisé des cas de figure alternatifs quant aux possibles comportements des utilisateurs, par rapport à la moyenne des dépenses observée et avec différentes probabilités d’occurrence. Avec le temps et l’observation des comportements, ces probabilités seront de mieux en mieux cernées. Et l’on pourra déterminer des corrélations entre les mouvements en comptes qui affineront encore les prévisions. Finalement, en ajustant ces dernières chaque jour aux événements en compte réels, l’appli sera à même de fournir une estimation de plus en plus fiable, proche du solde effectif de fin de mois, quel que soit le comportement des utilisateurs.
 Tout ceci est présenté comme un apport propre de l’IA mais, en matière de probabilités, il s’agit d’un raisonnement bayésien très classique. Dont on peut en l’occurrence se demander s’il ne conduit pas à adopter une démarche assez absurde !
Tout ceci est présenté comme un apport propre de l’IA mais, en matière de probabilités, il s’agit d’un raisonnement bayésien très classique. Dont on peut en l’occurrence se demander s’il ne conduit pas à adopter une démarche assez absurde !
L’idée retenue est apparemment que les utilisateurs ne jugeront la prévision de leur solde en compte de fin de mois véritablement utile que si elle est parfaitement fiable. Et elle ne leur paraitra telle que si elle prend en compte des dépenses qu’ils n’ont même pas encore l’idée de faire ! On s’efforce donc de prévoir, en comptant sur une régularité statistique de mieux en mieux affinée, le comportement des clients comme malgré eux et quoiqu’ils fassent. On présente cela comme une personnalisation des services alors qu’il s’agit d’une classique démarche de régulation de flux, qui traite les clients en masse. Cela est si vrai que, dès qu’un comportement va s’écarter du profil probabiliste qu’on lui prête a priori, l’utilisateur en sera averti à travers l’appli pour savoir si les opérations ne sont pas anormales.
Or, est-ce vraiment ce que les clients attendent ? Ne peuvent-ils parfaitement comprendre que la prévision se limite à des charges répétitives – mais que l’on oublie souvent, de sorte que leur rappel peut être très utile – et ne peuvent-ils souhaiter dès lors pouvoir l’utiliser pour calculer eux-mêmes l’impact de dépenses imprévues ? Plutôt que de leur fournir de manière complexe une prévision, ne conviendrait-il pas mieux de leur fournir des données plus limitées mais à leur main ? Un calculateur qui leur permette de projeter eux-mêmes l’impact de leurs dépenses. Un outil plus simple mais plus utile et qui rende les clients actifs.
En conclusion de l’article, son auteur dit être convaincu qu’avec la méthode qu’il décrit, la pertinence des résultats ne cessera d’augmenter, tant en termes d’applications concrètes que d’intérêt pour la recherche appliquée et universitaire ! Ne sommes-nous pas, plutôt que dans une démarche d’expérience client, face à un fantasme d’ingénieur, voulant automatiser les comportements et les traiter comme des choses ?
Dans le domaine de la banque digitale, ces approches qui reviennent pratiquement à se passer des clients eux-mêmes sont nombreuses. On parle ainsi de maturité des banques face aux données clients qu’elles sont à même de collecter et d’utiliser. Depuis un niveau d’agrégation peu fiable jusqu’à des dispositifs analytiques qui éclairent toutes les actions, en puisant à de multiples sources.
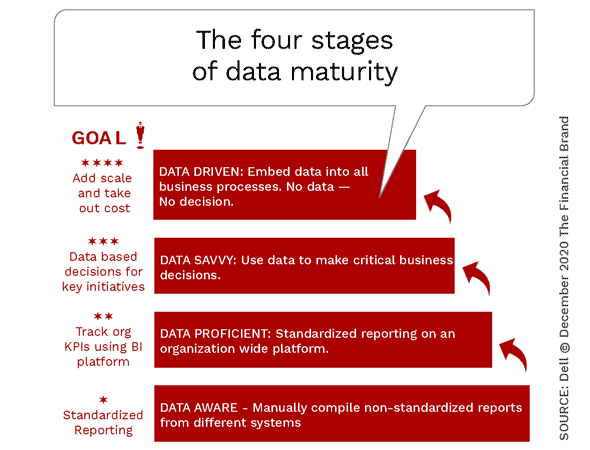
En quoi n’est absolument pas pris en compte un niveau de maturité vraiment essentiel : la capacité à réaliser en quoi et comment la mobilisation de données peut paraitre véritablement éclairante et nouvelle aux clients.
Score Advisor





